I've been learning TensorflowJS and Machine Learning, as an experiment, I thought I would implement a search across my current blog posts using sentence similarity on natural language, running in the browser.
In this post i'll go into how you can get started using pre-trained Tensorflow models to do Machine learning in the browser, examine some of the potential gotchas, such as not blocking the main thread with custom logic and consider the impact of the size of models on UX.
The demo that I developed as part of this article is a "search engine" using my blog posts as a data set, which I converted into an API, the idea being: can I find blog posts based on a search query by a user, by comparing the similarity of the query with a blog posts title and description?
Search is a solved problem and there are better ways of achieving the same thing, but I created this to learn and to have a bit of fun!
If you want to check out a live demo for what I built in this post, I've hosted it on my website.
Sentence similarity with TensorflowJS
I'm going to explain how this all works with a smaller example rather than the full demo that I linked earlier, but the source code for the example is available on Github, it's the same code, just with things like UI simplified.
First up, let's load in the library we are going to use. We're just going to load them from a CDN, when you're just experimenting, you don't want to be messing around with build processes.
Create a HTML file called index.html, with the following content:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Blog post search</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/universal-sentence-encoder"></script>
</head>
<body>
<script type="module" src="index.js"></script>
</body>
</html>We're loading in two libraries here, the first is TensorflowJS and the second is a the Universal Sentence Encoder model, which uses TensforflowJS, you can read about over here.
If you want to code along, host your files on a local dev server. I personally recommend the Live Server VS Code extension.
Next, create index.js add the following code:
// IIFE - because no top level await in all browsers at time of writing.
(async () => {
// download the model
const model = await use.load();
const blogPosts = [
"How I got started with 11ty",
"Building a responsive, progressively enhanced, masonry layout with only CSS and HTML",
"Using the Web Share API and meta tags, for simple native sharing",
"Tips for debugging in 11ty",
];
const userQuery = "Sharing to social media";
// embed the user input and the blog posts using the model - explained next!
const blogPostsTensor = await model.embed(blogPosts);
const userInputTensor = await model.embed([userQuery]);
})();In Chrome, and other browsers soon, you won't need to wrap the code in an IIFE because you could use top level await instead.
This code is loading the model, and then passing our userQuery of "Sharing to social media" and our array of blogPosts into the model.
Doing this converts the sentences into vectors (arrays) with 512 entries in the vector for each sentence, this is how the model sees the sentence.
Universal sentence encoder has been trained on a large vocabulary and is encoding the provided data based on the data it saw during training.
To help make this a bit clearer, blogPostsTensor and userInputTensor will be an instance of tensor2d.
These are 2D arrays (on the GPU) with 512 entries in each of the arrays, which represents a provided phase.
// The following are example embedding output of 512 dimensions per sentence
// Embedding for user input: "Sharing to social media"
// userInputTensor = tf.tensor2d([[0.01305108 0.02235125 -0.03263278, ...]])
// Embedding for: I am a sentence for which I would like to get its embedding.
// blogPostsTensor = tf.tensor2d([[0.05833394 -0.0818501 0.06890938, ...], [0.05833394 -0.0818501 0.06890938, ...]])Next, in order to find potentially good results based our input sentence we need to check how similar our input vector is to the vectors of the blog post titles, we can achieve this by calculating Cosine Similarity between the vectors, which will give us a value between -1 and 1. 1 being most similar and -1 being not very similar at all.
I'm not going to explain the mathematics of cosine similarity, but I've provided an implementation of it.
If you want to know how it works, there are lots of great explanations on YouTube, such as this one..
Define these at the top of your index.js file.
// multiply with value with corresponding value in the other array at the same index, then sum.
const dotProduct = (vector1, vector2) => {
return vector1.reduce((product, current, index) => {
product += current * vector2[index];
return product;
}, 0);
};
// square each value in the array and add them all up, then square root.
const vectorMagnitude = (vector) => {
return Math.sqrt(
vector.reduce((sum, current) => {
sum += current * current;
return sum;
}, 0)
);
};
const cosineSimilarity = (vector1, vector2) => {
return (
dotProduct(vector1, vector2) /
(vectorMagnitude(vector1) * vectorMagnitude(vector2))
);
};I tried to implement this maths purely in TensorflowJS, so that I could take advantage of the GPU, but after much trial and error, I could not find a solution. If anyone knows how to do this I'd love to hear about it. Doing this calculation myself is performing a large tradeoff of having these calculations happen on the main thread, which can cause bad UX, i'll explain this in more detail towards the end of the post, including ways around this.
Now lets use the functions in our code,
(async () => {
// download the model
const model = await use.load();
const blogPosts = [
"How I got started with 11ty",
"Building a responsive, progressively enhanced, masonry layout with only CSS and HTML",
"Using the Web Share API and meta tags, for simple native sharing",
"Tips for debugging in 11ty",
];
const userQuery = "Sharing to social media";
// embed the user input and the blog posts using the model - explained next!
const blogPostsTensor = await model.embed(blogPosts);
// wrap the user input in an array so model can work with it
const userInputTensor = await model.embed([userQuery]);
// == New code starts here //
// convert to JS arrays from the tensors
const inputVector = await userInputTensor.array();
const dataVector = await blogPostsTensor.array();
// this is an array of arrays, we only care about one piece of user input, one search query so
const userQueryVector = inputVector[0];
// how many results do i want to show
const MAX_RESULTS = 2;
// loop through the blog post data
const predictions = dataVector
.map((dataEntry, dataEntryIndex) => {
// COSINE SIMILARITY - compare the user input tensor with each blog post.
const similarity = cosineSimilarity(userQueryVector, dataEntry);
return {
similarity,
result: blogPosts[dataEntryIndex],
};
// sort descending
})
.sort((a, b) => b.similarity - a.similarity)
.slice(0, MAX_RESULTS);
document.querySelector("#initial-example-results").innerText = JSON.stringify(
predictions,
null,
2
);
})();On the last line of the above example we're updating the text of an element with id "initial-example-results", to make this work, let's add the following to your html file, inside the <body> tag.
<p>
This will take a few moments for the model to load and run. Query: "Sharing to
social media"
</p>
<pre id="initial-example-results"></pre>Here's a link to the code we've built so far: https://codesandbox.io/s/tensorflow-js-hardcoded-blog-search-0q5o9
<p>
This will take a few moments for the model to load and run. Query: "Sharing to
social media"
</p>
<pre id="initial-example-results"></pre>const dotProduct = (vector1, vector2) => {
return vector1.reduce((product, current, index) => {
product += current * vector2[index];
return product;
}, 0);
};
const vectorMagnitude = (vector) => {
return Math.sqrt(
vector.reduce((sum, current) => {
sum += current * current;
return sum;
}, 0)
);
};
const cosineSimilarity = (vector1, vector2) => {
return (
dotProduct(vector1, vector2) /
(vectorMagnitude(vector1) * vectorMagnitude(vector2))
);
};
/* swap out this.querySelectorDeep for document.querySelector, this is custom for my website demos */
this.querySelectorDeep("#initial-example-results").innerText =
"Downloading model...";
const model = await use.load();
const blogPosts = [
"How I got started with 11ty",
"Building a responsive, progressively enhanced, masonry layout with only CSS and HTML",
"Using the Web Share API and meta tags, for simple native sharing",
"Tips for debugging in 11ty",
];
const userQuery = "Sharing to social media";
this.querySelectorDeep("#initial-example-results").innerText =
"Encoding data...";
const blogPostsTensor = await model.embed(blogPosts);
const userInputTensor = await model.embed([userQuery]);
/* convert to JS arrays from the tensors */
const inputVector = await userInputTensor.array();
const dataVector = await blogPostsTensor.array();
/* this is an array of arrays, we only care about one piece of user input, one search query so */
const userQueryVector = inputVector[0];
/* how many results do i want to show */
const MAX_RESULTS = 2;
this.querySelectorDeep("#initial-example-results").innerText =
"Cosine similarity calculations...";
/* loop through the blog post data */
const predictions = dataVector
.map((dataEntry, dataEntryIndex) => {
/* compare the user input tensor with tensor of a blog post. */
const similarity = cosineSimilarity(userQueryVector, dataEntry);
return {
similarity,
result: blogPosts[dataEntryIndex],
};
/* sort descending */
})
.sort((a, b) => b.similarity - a.similarity)
.slice(0, MAX_RESULTS);
console.log(predictions);
this.querySelectorDeep("#initial-example-results").innerText = JSON.stringify(
predictions,
null,
2
);Turning posts into an API
My blog is written using the static site generator tool Eleventy. If you haven't heard of Eleventy and you're into building fast websites, seriously check it out, it's awesome. I'm not going to explain how Eleventy works, but I wrote a post about how I got started with Eleventy.
To create an API out of my blog posts I generate a JSON file in the form of a JSON Feed, which can be hosted on my server.
Here's my template for my json feed, this template is based on the 11ty base blog. The templating syntax being used is Nunjucks, and comes supported out of the box with Eleventy.
If you are curious and want to check out the source code of my blog it's over here on Github.
---
# Metadata comes from _data/metadata.json
permalink: "{{ metadata.jsonfeed.path | url }}"
eleventyExcludeFromCollections: true
---
{ "version": "https://jsonfeed.org/version/1", "title": "{{ metadata.title }}",
"home_page_url": "{{ metadata.url }}", "feed_url": "{{ metadata.jsonfeed.url
}}", "description": "{{ metadata.description }}", "author": { "name": "{{
metadata.author.name }}", "url": "{{ metadata.author.url }}" }, "items": [ {%-
for post in collections.posts | reverse %} {%- set absolutePostUrl %}{{ post.url
| url | absoluteUrl(metadata.url) }}{% endset -%} { "id": "{{ absolutePostUrl
}}", "url": "{{ absolutePostUrl }}", "title": "{{ post.data.title }}", "tags": [
{%- for tag in helpers.removeCollectionTags(post.data.tags) -%} "{{tag}}" {%- if
not loop.last %}, {%- endif %} {%- endfor %}], "summary": "{{
post.data.description }}", "content_html": {% if post.templateContent %}{{
post.templateContent | dump | safe }}{% else %}""{% endif %}, "date_published":
"{{ post.date | rssDate }}" } {%- if not loop.last -%} , {%- endif -%} {%-
endfor %} ] }This template is iterating through my blog posts and populating a JSON array with post data, as well as some other site metadata, ultimately the result is a JSON file which i can request on my server: https://griffa.dev/feed/feed.json.
Now I have an API which I can use in my search, success!
We can now update our code sample to pull data from this api instead of hard-coding it.
Add this function to the top of "index.js".
const loadBlogPosts = async () => {
const res = await fetch("https://griffa.dev/feed/feed.json");
const feed = await res.json();
return feed.items.map((item) => {
return {
/* search on title and summary */
searchData: `${item.title} ${item.summary}`,
title: item.title,
description: item.summary,
};
});
};Replace the following code:
const model = await use.load();
const blogPosts = [
"How I got started with 11ty",
"Building a responsive, progressively enhanced, masonry layout with only CSS and HTML",
"Using the Web Share API and meta tags, for simple native sharing",
"Tips for debugging in 11ty",
];with:
const [model, blogPosts] = await Promise.all([use.load(), loadBlogPosts()]);Also replace
const blogPostsTensor = await model.embed(blogPosts);with:
const blogPostsTensor = await model.embed(
blogPosts.map(({ searchData }) => searchData)
);<p>
This will take a few moments for the model to load and run. Query: "Building a
blog with javascript"
</p>
<pre id="initial-example-results"></pre>const dotProduct = (vector1, vector2) => {
return vector1.reduce((product, current, index) => {
product += current * vector2[index];
return product;
}, 0);
};
const vectorMagnitude = (vector) => {
return Math.sqrt(
vector.reduce((sum, current) => {
sum += current * current;
return sum;
}, 0)
);
};
const cosineSimilarity = (vector1, vector2) => {
return (
dotProduct(vector1, vector2) /
(vectorMagnitude(vector1) * vectorMagnitude(vector2))
);
};
/* swap out this.querySelectorDeep for document.querySelector, this is custom for my website demos */
this.querySelectorDeep("#initial-example-results").innerText =
"Downloading model and blog posts...";
const loadBlogPosts = async () => {
const res = await fetch("https://griffa.dev/feed/feed.json");
const feed = await res.json();
return feed.items.map((item) => {
return {
/* search on title and summary */
searchData: `${item.title} ${item.summary}`,
title: item.title,
description: item.summary,
};
});
};
const [model, blogPosts] = await Promise.all([use.load(), loadBlogPosts()]);
const userQuery = "Building a blog with javascript";
this.querySelectorDeep("#initial-example-results").innerText =
"Encoding data...";
/* extract the searchData from the blog posts */
const blogPostsTensor = await model.embed(
blogPosts.map(({ searchData }) => searchData)
);
/* wrap the user input in an array so model can work with it */
const userInputTensor = await model.embed([userQuery]);
/* convert to JS arrays from the tensors */
const inputVector = await userInputTensor.array();
const dataVector = await blogPostsTensor.array();
/* this is an array of arrays, we only care about one piece of user input, one search query so */
const userQueryVector = inputVector[0];
/* how many results do i want to show */
const MAX_RESULTS = 5;
this.querySelectorDeep("#initial-example-results").innerText =
"Cosine similarity calculations...";
/* loop through the blog post data */
const predictions = dataVector
.map((dataEntry, dataEntryIndex) => {
/* compare the user input tensor with tensor of a blog post. */
const similarity = cosineSimilarity(userQueryVector, dataEntry);
return {
similarity,
result: blogPosts[dataEntryIndex],
};
/* sort descending */
})
.sort((a, b) => b.similarity - a.similarity)
.slice(0, MAX_RESULTS);
console.log(predictions);
this.querySelectorDeep("#initial-example-results").innerText = JSON.stringify(
predictions,
null,
2
);Here's a link to the code we've built so far: https://codesandbox.io/s/tensorflow-js-blog-search-3k7x2
ML in the browser, why?
Hopefully the examples so far have made sense, I thought i'd take a moment to talk about some of benefits and tradeoffs of doing Machine learning in the browser with TensorflowJS.
One of the first things you might think of when you think Machine learning in JavaScript is it's slow, well that's where one of the great things about TensorflowJS comes in, it performs all of its expensive calculations on the GPU, under the hood it's utilising WebGL shader programs to achieve this.
Running Machine learning in the browser opens up the possibilities of offering Machine learning in applications without needing to build complex server architectures, or learning another language. It also means that it's possible to provide on-device Machine learning to users, without their data ever hitting a server.
One of the other great things about the JavaScript ecosystem is its ability to not just run in the browser, but on the server too, with NodeJS. TensorflowJS is also available in Node JS, where it can be bound directly to the Tensorflow API, the same API that the python implementations of the library consume. I've considered the possibility of modifying my experiment in this blog post so that when I generate my static site at build time with Eleventy, I could run the model against my data and pre-generate the data for my blog posts, that might be cool.
The final great thing is that it is possible to convert/re-use models created by the other Tensorflow ecosystems (Python etc) so that they run in the browser.
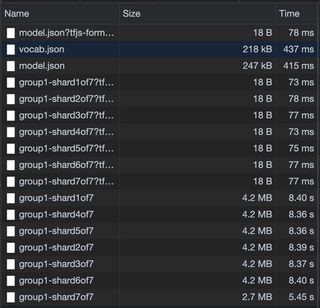
Now for one of the big trade offs, Machine learning models can be large, there is a lot of work going to make these models smaller and smaller, but the model used in this demo for example is approximately 28 MB. To be fair, for a general purpose natural language model, this is quite impressively small. Many of these models, are split into chunks so that the model can be downloaded in parallel, which improves things a bit. This tradeoff might be acceptable if it unlocks the ability to provide a good enough UX, without the need to hit a server, which once the model is downloaded can be lightning fast. The model can only be as fast the end-user machine it's running on, which, especially on mobile, can vary dramatically.
In applications you might be able to do some different things to make this tradeoff worth it, for example:
- Enabling good caching headers
- Using service workers to background fetch and cache the model, and enable the feature
- Allowing users to opt in/out
- Offer the feature as a progressive enhancement that enables once downloaded
With the above tradeoffs in mind it might, or might not, make sense to do ML in the browser. Where you need to try and run your models immediately as the site/app loads, or end user device constraints are a problem, maybe server side is the better choice.
When using JavaScript it's always important to not block the main thread, I mentioned above that Tensorflow utilises the GPU for its calculations, but as soon as you stop using its API you're back in the JS main thread, and if you perform expensive calculations there ,you are at risk of providing a bad UX to your users.
The sample in this post is guilty of this, when performing the cosineSimilarity calculations, let's fix it.
Unblocking the main thread
In the browser you can create additional threads called "Workers", these are isolated threads, that do not have access to any DOM APIs, or variables in the main thread.
The only way to communicate between the main thread is via postMessage, which can be cumbersome.
There is an absolutely fantastic library Comlink that makes working with Worker threads basically invisible, it allows you to work with functions as if they were on the main thread, I believe it achieves this using Proxy objects, hiding the need to work with postMessage directly 🎉.
Let's convert our example to use Comlink and move our maths off the main thread.
We're going to import the Tensorflow libraries in our worker instead so your HTML should look like this.
Let's also add in some user input, to make the demo a bit more spicy.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Blog post search</title>
</head>
<body>
<script type="module" src="index.js"></script>
<form id="search">
<input disabled name="query" type="text" />
<button disabled>Search</button>
</form>
<pre id="initial-example-results"></pre>
</body>
</html>Next up, delete all of the code in "index.js". Now in "index.js" lets add the code to work with our new "worker.js" file and update the UI.
We're going to add all of the same code, except this time, expose a function called "search" which returns our predictions.
There are few other changes too, such as using importScripts to import the libraries into the Worker.
importScripts("https://unpkg.com/comlink/dist/umd/comlink.min.js");
importScripts("https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@latest");
importScripts(
"https://cdn.jsdelivr.net/npm/@tensorflow-models/universal-sentence-encoder"
);
let model;
let blogPosts;
const loadBlogPosts = async () => {
// fetch + cache comparison data
const res = await fetch("https://griffa.dev/feed/feed.json");
const feed = await res.json();
const data = feed.items.map((item) => {
return {
searchData: `${item.title} ${item.summary}`,
title: item.title,
description: item.summary,
};
});
return data;
};
const loadModel = async () => {
const model = await use.load();
return model;
};
const load = async () => {
[model, blogPosts] = await Promise.all([loadModel(), loadBlogPosts()]);
};
//// cosine similarity fns
const dotProduct = (vector1, vector2) => {
return vector1.reduce((product, current, index) => {
product += current * vector2[index];
return product;
}, 0);
};
const vectorMagnitude = (vector) => {
return Math.sqrt(
vector.reduce((sum, current) => {
sum += current * current;
return sum;
}, 0)
);
};
const cosineSimilarity = (vector1, vector2) => {
return (
dotProduct(vector1, vector2) /
(vectorMagnitude(vector1) * vectorMagnitude(vector2))
);
};
////
async function search(userQuery) {
const blogPostsTensor = await model.embed(
blogPosts.map(({ searchData }) => searchData)
);
const userInputTensor = await model.embed([userQuery]);
const inputVector = await userInputTensor.array();
const dataVector = await blogPostsTensor.array();
/* this is an array of arrays, we only care about one piece of user input, one search query so */
const userQueryVector = inputVector[0];
/* how many results do i want to show */
const MAX_RESULTS = 5;
/* loop through the blog post data */
const predictions = dataVector
.map((dataEntry, dataEntryIndex) => {
/* compare the user input tensor with tensor of a blog post. */
const similarity = cosineSimilarity(userQueryVector, dataEntry);
return {
similarity,
result: blogPosts[dataEntryIndex],
};
/* sort descending */
})
.sort((a, b) => b.similarity - a.similarity)
.slice(0, MAX_RESULTS);
return predictions;
}
const SearchService = {
search,
load,
};
/* expose the SearchService api to comlink */
Comlink.expose(SearchService);Now, let's use our new SearchService in "index.js".
import * as Comlink from "https://unpkg.com/comlink@4.3.0/dist/esm/comlink.min.mjs";
const worker = new Worker("worker.js");
const SearchService = Comlink.wrap(worker);
(async () => {
document.querySelector("#initial-example-results").innerText =
"Loading model...";
await SearchService.load();
document.querySelector('#search input[name="query"]').disabled = false;
document.querySelector("#search button").disabled = false;
document.querySelector("#initial-example-results").innerText =
"Model loaded, try out some queries e.g. Building a blog with JavaScript";
document.querySelector("#search").addEventListener("submit", async (e) => {
e.preventDefault();
const data = new FormData(e.target);
const query = data.get("query");
document.querySelector("#initial-example-results").innerText =
"Searching...";
const predictions = await SearchService.search(query);
document.querySelector("#initial-example-results").innerText =
JSON.stringify(predictions, null, 2);
});
})();If you load this demo code up in the browser you should get similar result to before, but with the heavy-work offloaded to a Worker thread.
Here's a live demo project for reference: https://codesandbox.io/s/tensorflow-js-with-web-workers-blog-searching-1shbq
Hopefully you can see from the example how you can offload work into a worker using Comlink, you can also build for production using popular tools such as Rollup, but I won't cover that here.
One of the neat things about using Worker threads is because they don't have access to the DOM you are forced to separate your application logic from your UI, making your code more modular and reusable in the future.
Future thoughts
In case you missed the links earlier:
- Source code: https://github.com/Georgegriff/griffadev/tree/main/src/demos/natural-language-search
- Demo: https://griffa.dev/demos/natural-language-search/
If I was to continue this idea through i'd probably explore some of the following:
- Making the code more production ready using module imports and a build tool chain.
- Investigate ways to use TensorflowJS at build time of my blog to pre-calculate embeddings for posts.
- See if there is in-fact ways to do cosine similarity directly in TensorflowJS, again, i'd love to know if anybody knows how!
I hope to continue my Machine learning journey, I have some other blog related ideas that I might try to explore in the future:
- Recommending similar blog posts
- Text summary generation of blog posts.
I'm fairly early on in my AI learning journey, but one of the initial resources that helped me out and inspired me was watching content from Jason Lengstorf from his Learn with Jason series, which I highly recommend. One of the truly awesome things about this series is closed captioning is provided, making this content more accessible to everybody 🎉.
At the time of writing there are 3 sessions relating to Machine Learning and TensorflowJS, here is one of them:
I hope this was a good read, if you feel like reading more of my work, please follow me on X @griffadev, or get me a coffee if you feel like it ☕.